Abstract
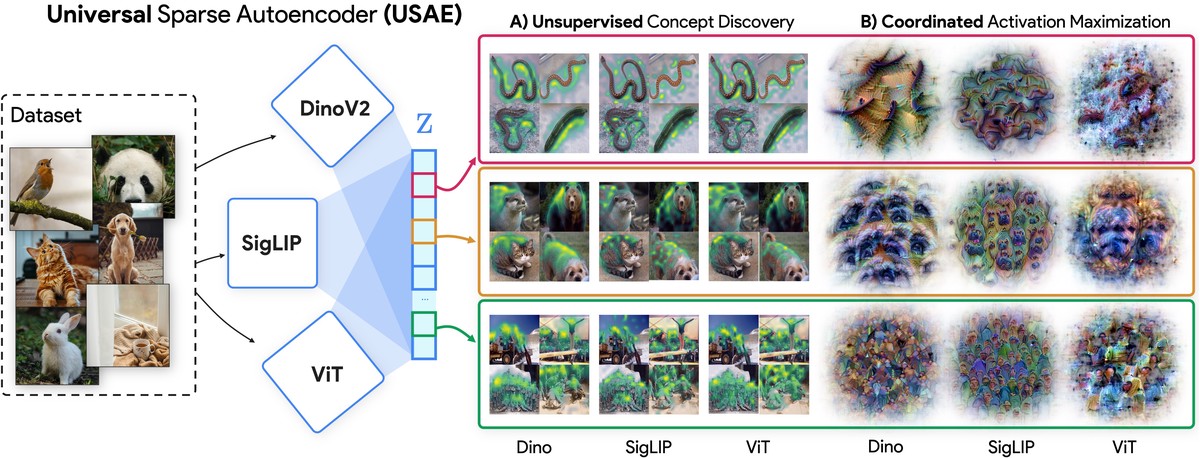
We present a framework for discovering interpretable concepts that span multiple neural networks. We develop a single sparse autoencoder that can process activations from different models and reconstruct activations across models. Our method identifies semantically coherent and important universal concepts ranging from low-level features like colors and textures to higher-level structures including parts and objects, enabling cross-model analysis.
Type
Publication
International Conference on Machine Learning (ICML), 2025