Harry Thasarathan
Graduate Researcher
York University
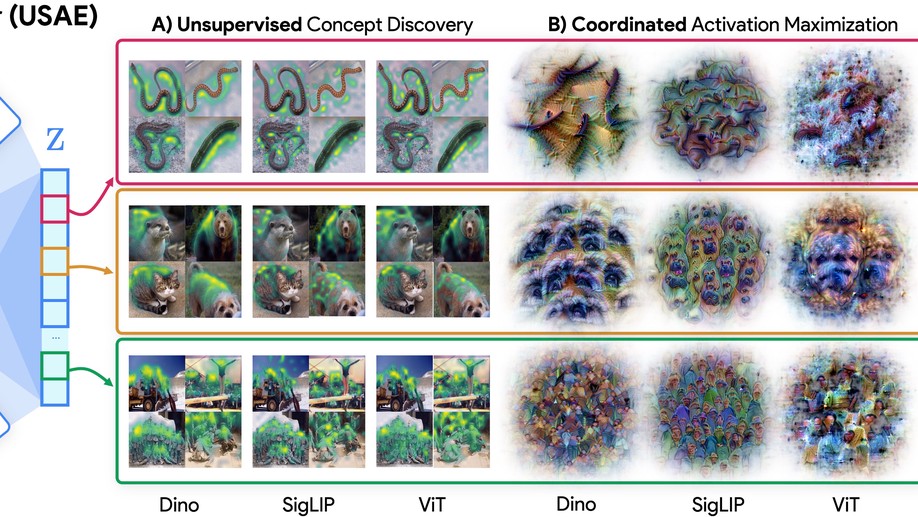
I am a PhD student at York University and a member of CVIL, supervised by Kosta Derpanis. My research uses vision models as a testbed for developing interpretability methods that enable both scientific understanding and practical control of neural network representations.
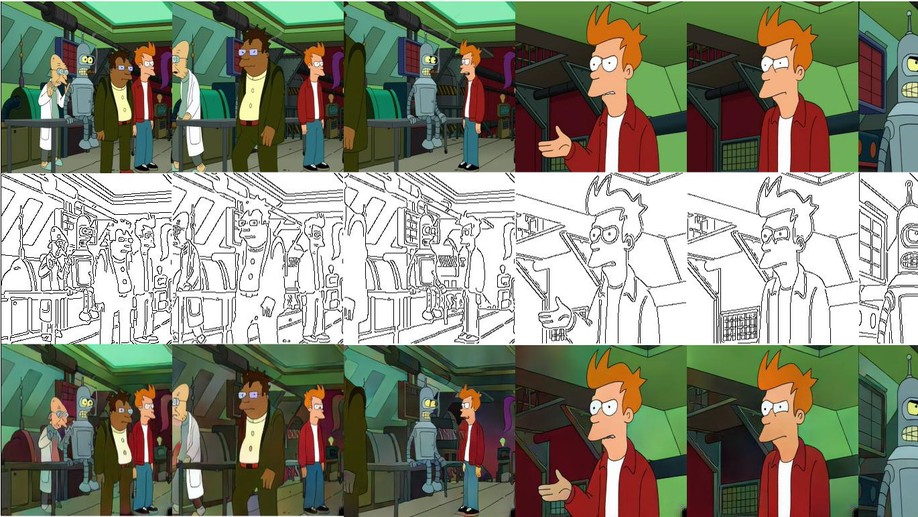
Previously, I completed my Master’s with Kosta Derpanis and Marcus Brubaker, where I worked on long-term 3D human pose forecasting through keyframe-based motion representations. During my undergraduate studies at Ontario Tech, I explored structured generative models for 3D human locomotion with Faisal Qureshi and Ken Pu, and worked on temporal coherence in GANs for video colorization and super-resolution with Mehran Ebrahimi and Kamyar Nazeri.
Interests
- Computer Vision
- Interpretability
- Generative Modelling
- Scientific Discovery
Education
-
PhD Computer Science
York University
-
MSc Computer Science, 2023
York University
-
BSc Computer Science, 2021
University of Ontario Institute of Technology